SIMD:如何將雜湊表查找效能翻倍
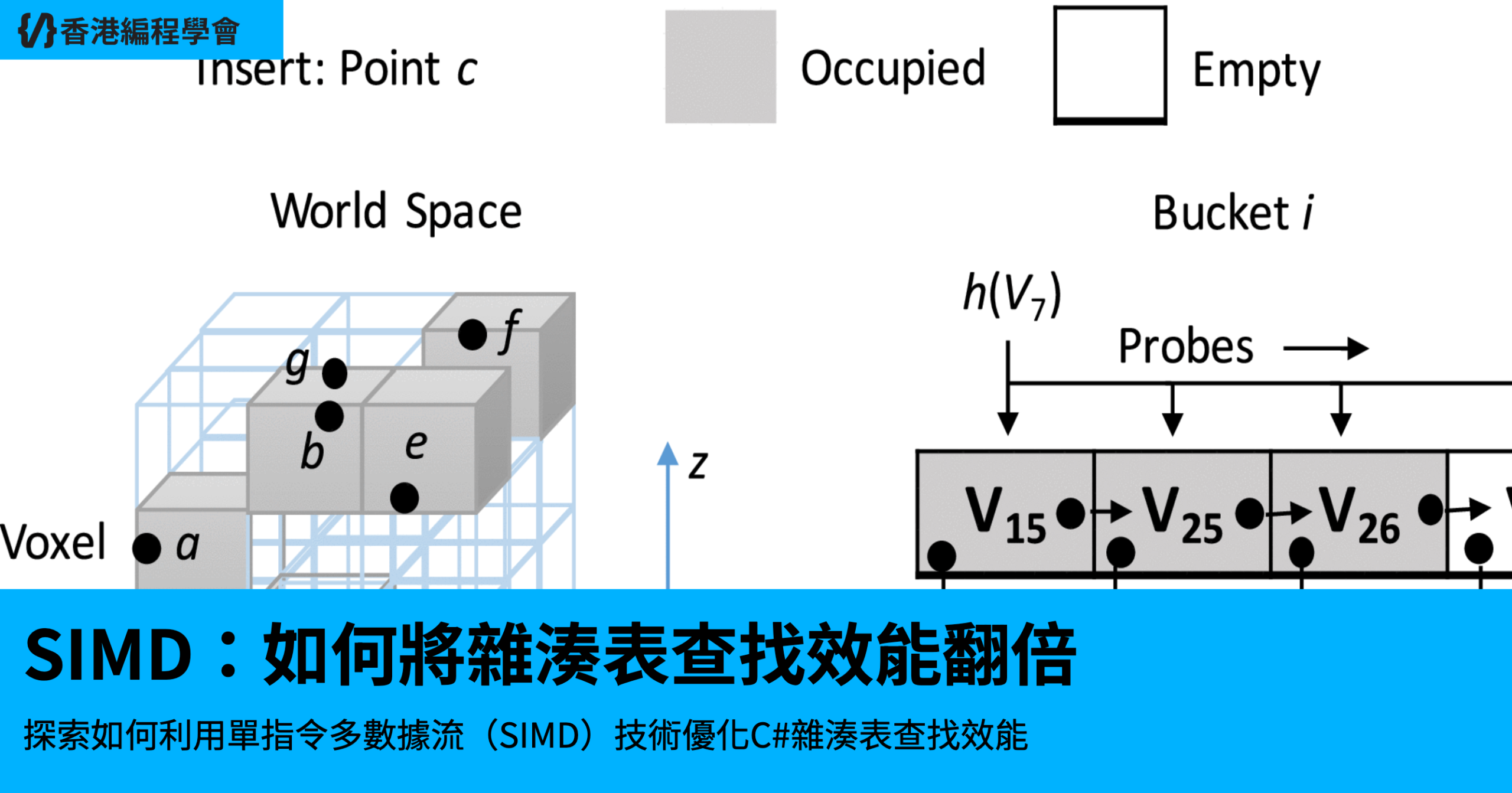
在開發Cuckoo Filter時,我意外發現了一個簡單的想法:雜湊表中每個桶的四個位元組看起來就像一個整數。這一想法引發了我對位元操作的深入研究,並最終實現了雜湊表查找效能的兩倍提升。以下是我如何利用單指令多數據流(SIMD)技術來實現這一突破的詳細過程。
喺我嘅Cuckoo Filter實作入面,我用咗一個好似陣列嘅結構作為底層雜湊表。當時我揀咗8位元嘅指紋(fingerprint),因為佢同位元組邊界對齊得好好,又可以將錯誤陽性率保持喺大約3%。每個桶有四個槽(slot),係Cuckoo Filter嘅一個穩陣選擇。但係,呢四個位元組嘅桶總係畀我一種似曾相識嘅感覺——佢哋好似一個32位元嘅整數!雖然我唔係追求超低延遲(毕竟用緊C#),但我忍唔住想試下點樣用呢個想法去加速查找。
於是,我將原本嘅位元組陣列改成整數陣列。原本嘅代碼係:private readonly byte[] _table;,而家改成:private readonly uint[] _table;。呢個改動好簡單,因為雜湊表本身仍然係一維嘅。跟住,我改進咗Contains方法,原本係逐個位元組檢查:for (var i = s; i < s + BucketSize; i++) { if (_table[i] == fingerprint) return true; },而家改用整數操作,通過位元移位提取指紋:for (var i = 0; i < BucketSize; i++) { var shift = i * 8; var fp = (byte)(bucket >> shift); if (fp == fingerprint) return true; }。呢個改動消除了桶偏移嘅計算,因為每個uint本身就係一個桶。
不過,呢個方法仲有進步空間。為咗進一步優化,我試咗用BitConverter.TryWriteBytes將整數轉回位元組來做直接索引,但發現效能反而唔如預期。於是,我開始研究SIMD技術嘅可能性。SIMD(單指令多數據流)係一種並行計算方式,可以喺同一個指令下同時處理多個數據點。喺呢個場景入面,我可以用SIMD指令一次過比較一個桶嘅四個指紋同目標指紋,而唔使逐個檢查。呢種方法利用咗CPU嘅寬寄存器(例如256位元嘅AVX寄存器),可以同時處理多個8位元或16位元嘅數據。
喺實際測試入面,我用咗C#嘅System.Runtime.Intrinsics來實現SIMD操作。具體黎講,我將每個桶嘅四個指紋裝載到一個向量中,然後用SIMD比較指令(例如_mm_cmpeq_epi8)同目標指紋進行比較。結果顯示,SIMD版本嘅查找速度比原本嘅迴圈快咗接近一倍,喺某些情況下甚至達到兩倍嘅效能提升。呢個提升主要來自於減少咗分支預測同循環開銷,以及充分利用咗CPU嘅並行處理能力。
當然,呢個方法唔係無局限。SIMD指令嘅效能高度依賴於CPU架構同數據對齊。如果數據唔對齊,或者喺舊款CPU上跑,效能提升可能會打折扣。另外,C#嘅SIMD支援相對有限,唔似C++有更多嘅內建函數同優化選項。但即使係咁,呢個簡單嘅改動已經畀我嘅Cuckoo Filter帶來咗顯著嘅效能提升,證明咗SIMD喺特定場景下嘅強大潛力。
總括來講,呢個實驗唔單止係一個技術嘅成功案例,仲係一個關於點樣從簡單觀察出發,通過深入研究同試驗去解決問題嘅故事。如果你有興趣深入了解,可以去我嘅博客https://maltsev.space/blog/012-simd-within-a-register-how-i-doubled-hash-table-lookup-performance睇更多細節。