Fluss重新定義實時流存儲,挑戰Kafka霸主地位
Apache Fluss 是一個專為實時分析同人工智能(AI)場景設計嘅流式存儲系統,目標係解決傳統架構中數據重複複製、成本高昂同延遲高等問題。佢基於 Apache Arrow 構建,採用列式日誌結構(columnar log),提供亞秒級讀寫延遲同強大嘅分析能力。Fluss 唔單止提升咗機器學習特徵工程同多模態 AI 數據攝入嘅效率,仲實現咗流批統一嘅數據處理,幫企業打造一個統一、高效、低成本嘅實時數據底座。
喺現今「數據驅動」嘅年代,Apache Kafka 一直係流式數據架構嘅核心,喺微服務間事件通信同高吞吐量日誌收集方面表現出色。但當需要從流數據中提取實時洞察時,企業通常會用 Apache Flink 進行處理同轉換,數據會被寫返 Kafka 嘅多層主題(Topic),例如青銅層(bronze)、銀層(silver)同金層(gold),形成所謂嘅「數據湖勳章架構」(Medallion Architecture)。不過,呢種方法往往導致數據重複存儲,增加成本同複雜性。Fluss 喺兩年前誕生,目的就係解決呢啲痛點,通過統一嘅存儲層,減少數據複製,提升效率。
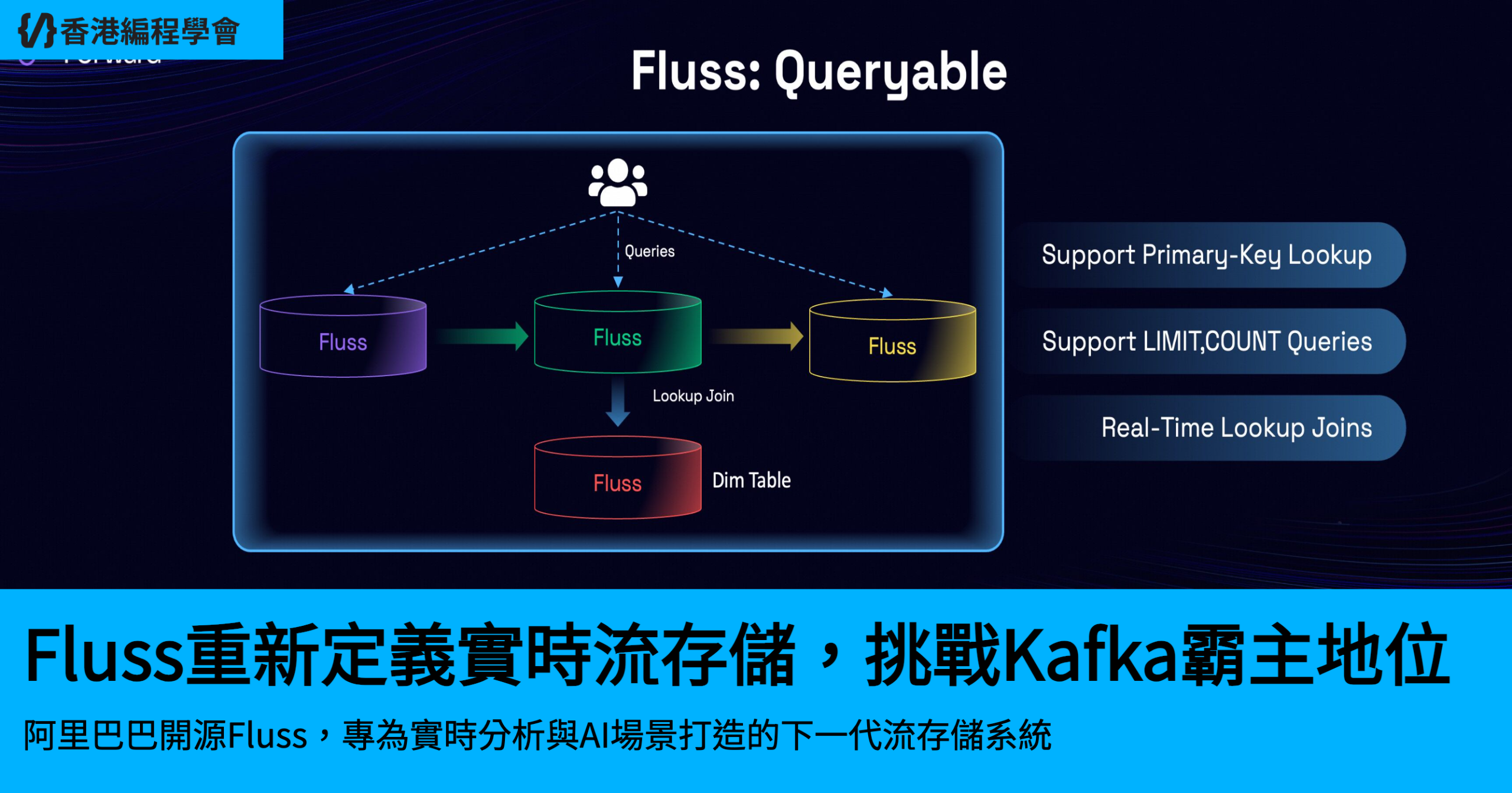
Fluss 嘅核心優勢在於佢嘅列式存儲同低延遲查詢能力。得益於 Apache Arrow 嘅列式格式,Fluss 支持流式列裁剪同分區裁剪,查詢時只讀取所需嘅列同分區,大幅降低網絡傳輸開銷,提升分析效率。同時,Fluss 提供高並發、低延遲嘅鍵值(KV)查詢同更新功能,可以直接作為 Flink 嘅維度表進行 Lookup Join,無需再引入 Redis 等額外組件。呢啲特性令 Fluss 喺實時數據處理中表現出色,特別適合需要快速響應嘅應用場景,例如金融交易、物聯網同實時推薦系統。
除此之外,Fluss 仲實現咗湖倉一體化嘅設計,將熱數據保留喺本地高速存儲,冷數據自動歸檔到湖倉(例如 Iceberg 或 Paimon),實現成本同性能嘅平衡。歸檔數據採用標準開放格式,可以直接被 Spark、Trino 同 StarRocks 等引擎讀取。Fluss 引入咗「統一讀取」(Union Read)特性,智能合併熱數據同冷數據,先讀取歷史數據,再無縫銜接實時流,確保無重複、無遺漏。呢種流批統一嘅能力,令企業可以用一份數據同時滿足實時同批量分析嘅需求,實現真正嘅數據融合。
Fluss 已經喺阿里巴巴大規模落地應用,展現出強大嘅穩定性同性能。據報導,Fluss 目前管理超過 3 PB 嘅數據,單集群寫入吞吐量高達 40 GB/s,支持單表 50 萬 QPS 嘅鍵值查詢,最大單表行數超過 5000 億。呢啲數字顯示咗 Fluss 喺處理巨量數據時嘅強大能力。與此同時,Fluss 喺 Flink Forward Asia 2024 正式開源,成為 Apache Flink 生態嘅重要一員,未來仲計劃同多模態 AI 同開放數據生態深度整合,進一步推動實時數據底座嘅發展。詳情請見:https://blog.csdn.net/lifallen/article/details/150388232